Research
Failure prediction and proactive maintenance
We have developed effective methods of failure prediction that can be used to avoid computer system failures or minimize their impact. Using such methods in proactive (predictive) maintenance may significantly reduce the total cost of ownership. We cover the entire process from monitoring, through feature selection and failure prediction to failure avoidance or impact minimization (see Figure 1). Please note that there is a number of research problems to be solved: we need to know what features to monitor, how frequently, with how many monitors including the placement of such monitors in preferably non-evasive manner. Selection of the most indicative features is another challenge, especially that our research shows that quality of features is more important than the quality of the model. Next we need to select or invent most effective prediction algorithm. Finally, once we know that there is an imminent failure we have to devise appropriate mitigation techniques.
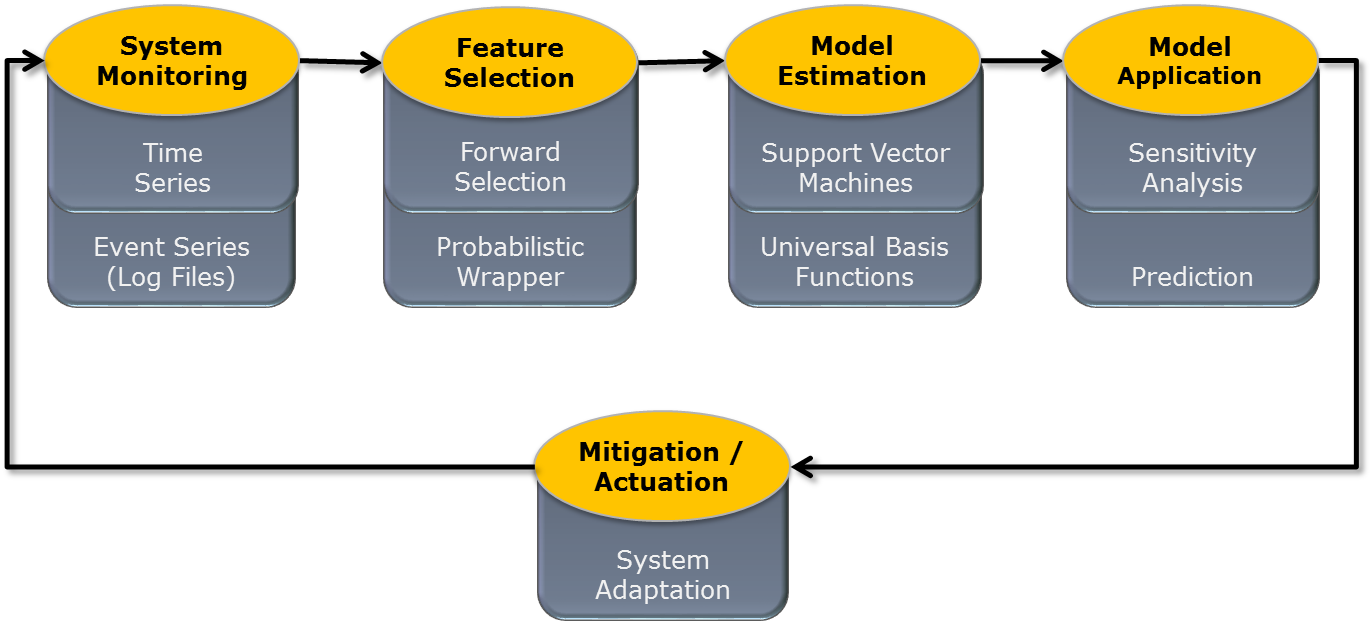
Figure 1: Methodology and sample methods for failure prediction
After successful applications in computer industry we also applied such methods for healthcare (heart failure prediction), early malware detection and power distribution networks (smart grids).
Dependability, real time, responsiveness and security
With ever-increasing system complexity, new services and new requirements keeping the systems running flawlessly is one of the main challenges. We focus on design of fault-tolerant and secure systems and services that can operate correctly even in the presence of faults. We address problems of diagnosis, recovery. I proposed comparison-based models for fault diagnosis whose applications range from selecting fault-free units on a wafer to identifying faulty servers in parallel and distributed systems. We also look at smart phone security and early attack detection in such systems using feature selection and machine learning.
Parallel, distributed and embedded systems
I codeveloped one of the first parallel computers based on banyan interconnection network called Texas Reconfigurable Array Computer (TRAC) and participated in the Research Parallel Processor Project (RP3) at IBM. This experience was transferred to distributed and embedded environments. One of our objectives is to successfully “marry” computer clouds and Internet of Things into an efficient, dependable and secure assembly of massive data processing. We research cooperative scheduling, consensus and localization/placement algorithms to accomplish this goal.